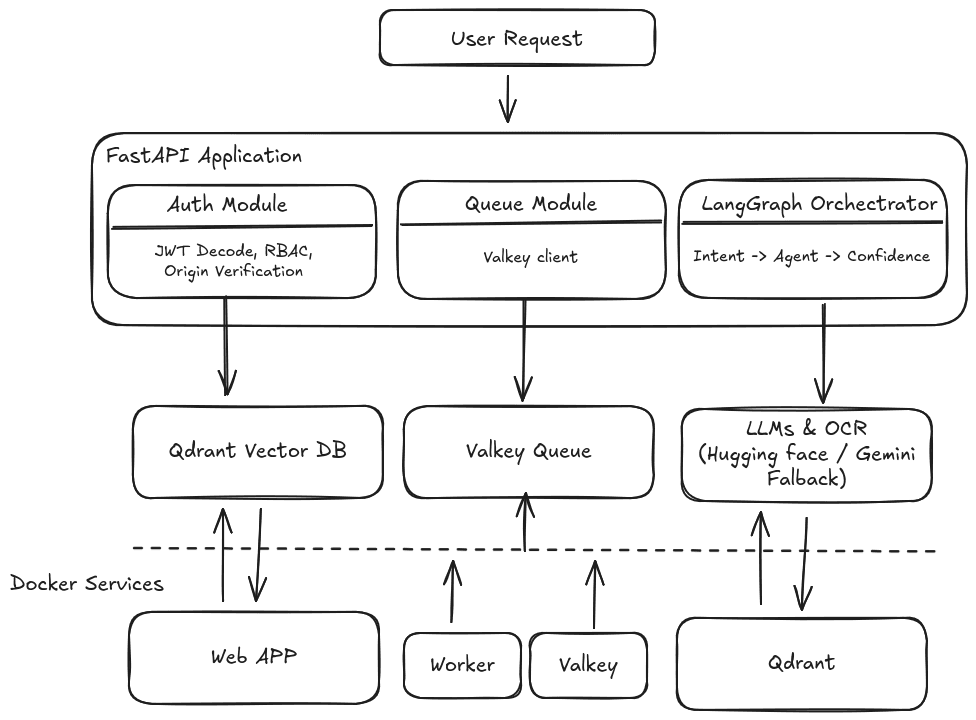
High-Level Architecture
At a glance, the system looks like this:
- FastAPI → API, auth, request lifecycle
- LangGraph → AI workflow orchestration
- Qdrant → Vector database for RAG
- Valkey (Redis-compatible) → Queues & analytics
- Huggingface + Gemini → LLM & embeddings
Chat Flow:
Here’s what happens when a user asks a question:
- Client sends message (POST /api/v1/chat)
- Auth & context loaded (JWT, headers, page location)
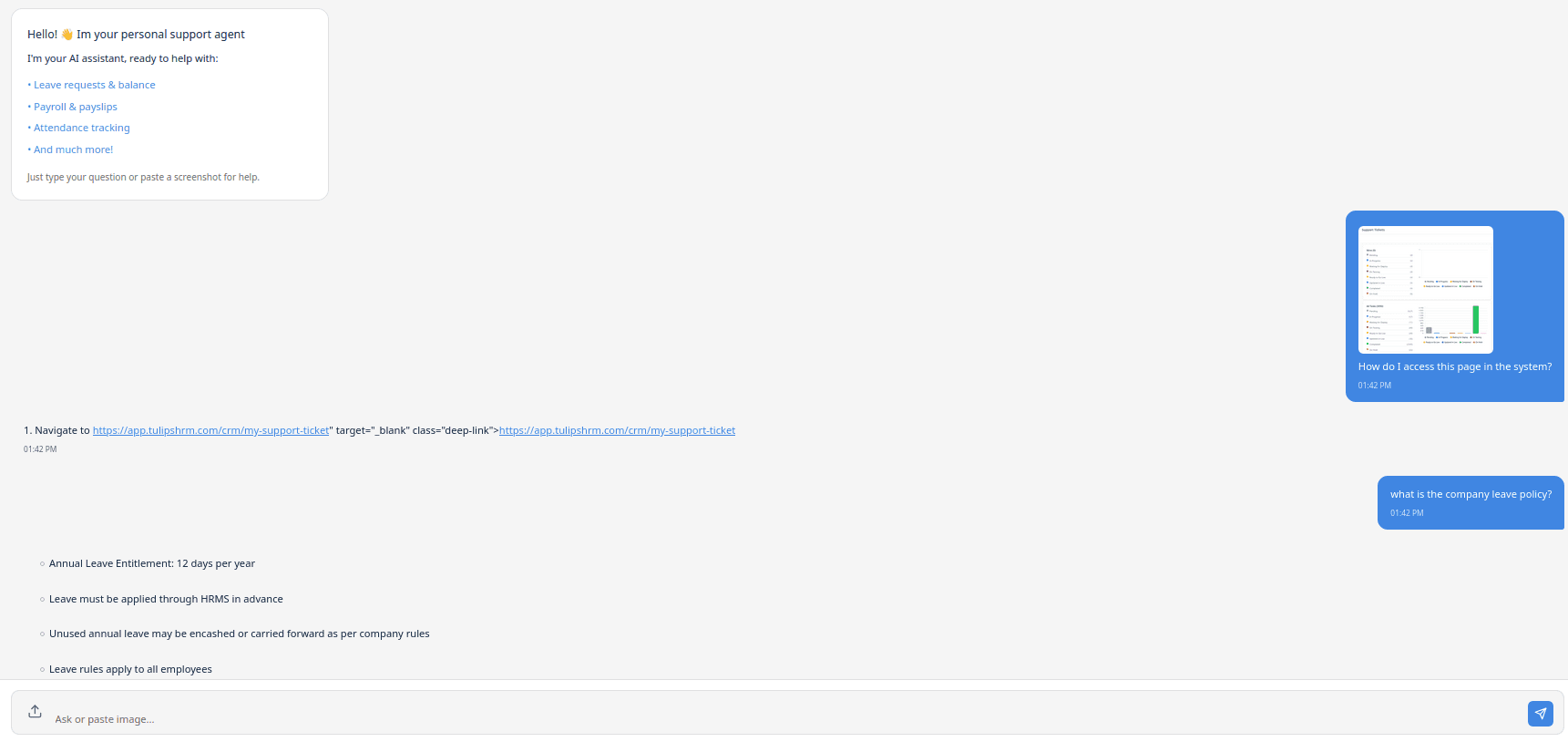
- Optional vision step (images → text)
- LangGraph orchestrator runs
- Intent is classified
- Correct agent is selected
- RAG retrieves documents (if needed)
- Confidence is evaluated
- Response is finalized or clarified
Intent Classification: The Brain Split
Every query is classified into one of four intents:
- How‑To → step-by-step guidance
- Policy → document-backed answers (RAG)
- Page Help → UI-aware assistance
- Unknown → fallback handling
Why LangGraph (Not Just Chains)
I chose LangGraph because:
- It supports branching logic
- Each agent is a node
- State is explicit and inspectable
- Confidence gating becomes trivial
RAG Document Ingestion
- When an admin uploads a document:
- Text is extracted (PDF/TXT/MD)
- Content is chunked with overlap
- Metadata is attached (type, title, status)
- Embeddings are generated
- Vectors are stored in Qdrant
Embedding Fallback
- Primary: HuggingFace embeddings
- Fallback: Gemini embeddings
Confidence-Aware Responses
After an agent generates a response, the system asks:
“How confident are we?”
If confidence ≥ threshold → answerIf
confidence < threshold → ask clarifying questions
Why Valkey
Every chat request is also:
- Logged asynchronously
- Analyzed for confidence drops
- Tracked for usage patterns
Using Valkey lets me:
- Avoid blocking requests
- Scale workers independently
- Improve the bot over time
Models Used (Free‑Tier Friendly)
Embedding Models:
- Primary: BAAI/bge-small-en-v1.5 (Hugging Face)
- 384‑dimension embeddings
- Excellent semantic retrieval quality for RAG
- Fast and lightweight
- Fallback: text-embedding-004 (Gemini)
- Automatically used if Hugging Face is rate‑limited or unavailable
Chat & Reasoning
- Hugging Face Chat & Confidence Models: Qwen/Qwen2.5-1.5B-Instruct
- Used for intent classification, lightweight responses, and confidence scoring
- Fully open-source and free-tier compatible
- Gemini Chat & Assistant: gemini-2.5-flash
- Handles complex reasoning and document-grounded responses
- Large context window for RAG answers
Vision / OCR
- Hugging Face Vision Model: Salesforce/blip-image-captioning-large
- Generates image captions and analyzes visual content
- Hugging Face OCR Model: microsoft/trocr-base-printed
- Extracts text from scanned documents and images
- Integrated into RAG ingestion pipeline
- Gemini OCR fallback: gemini-2.5-flash
- Used if Hugging Face OCR hits limits
Confidence Evaluation Model
- Confidence Model: gemini-2.5-flash
- Scores response reliability
- Powers the confidence gate that decides whether to answer or clarify
Why This Stack Is “Free”
- FastAPI – open source
- Qdrant – open source
- Valkey – open source
- LangGraph – open source
- Hugging Face Inference API – generous free tier
- Gemini API – free tier with key rotation